
本文研究现实中使用水印的可靠性,结论是,带水印的文本在被人类重写、由非带水印的LLM转述或混合成更长的手写文档后,水印仍然是可检测的;此外提出了对短跨度水印敏感的新检测方案
3 How to improve watermark reliability?
本节针对 Green List 进行改进,前面稍微介绍了一下 Green List
3.1 Improved Hashing Schemes
这节介绍几种 Green List scheme 的变体,能够提升 Green List 的表现。
首先,Green List scheme 的方案比较简单:随机数生成器使用$h = 1$进行播种,即仅使用位置$t−1$的那个token 来为位置 $t$ 的 token 上色(green/red)。此方案称为LeftHash。由于 green list 仅依赖于一个token,攻击者就可以通过搜索位置$t$上的后续单词来学习与位置$t−1$的 token 相关的 green list ,且这些单词在无水印分布下不太可能出现。在某些情况下,水印方案需要被保密起来隐藏在API之后,因此需要更安全的方案。
Kirchenbauer等人[2023]也提到了一种方案(Algorithm 3):位置 $t$ 的 green list 的生成除了依赖 $f$ 输入中 $t$ 左边的token,还依赖位置 $t$ 本身(尚未生成)的token。这种哈希方案称为SelfHash。该方法有效地将上下文宽度$h$增加了$1$,使得暴力破解方法更难发现水印规则。本文将此方案推广到包括任意函数 $f$ 和文本生成,详见附录算法1。
当上下文宽度 $h$ 增加以保持 red/green list 规则的保密性时,检测可靠性在很大程度上取决于哈希方案。
定义以下函数$f: \mathbb{N}^h→\mathbb{N}$,它们将标记 {$x_i$} 的空间映射到伪随机数上,每个都依赖于一个秘密盐值$s∈\mathbb{N}$和一个标准整数 PRF $P: \mathbb{N→N}$。
-
Additive:这是 Green List 原文提到的函数,这边将其扩展到$h>1$的情况,通过定义:$f_{Additive-LeftHash}(x)=P(s\sum^{h}_{i=1}{x_i})$。虽然上下文$x$的排列不会改变结果,但从$x$中删除或交换单个token会改变哈希值,从而破坏该token处的水印。
-
Skip:这个函数在上下文中只使用最左边的标记:$f_{Skip-LeftHash}(x)=P(sx_h)$。该散列对于非最左边令牌的更改是健壮的,但它容易受到插入或删除的影响。
-
Min:这个函数定义为:$f_{Min-LeftHash}(x)=min_{i \in 1,…,h}P(sx_i)$。它对上下文中的排列具有鲁棒性,对插入/删除具有部分鲁棒性。假设所有$P(sx_i)$都是伪随机的,并且同样可能是最小的值,那么该方案失败的可能性与从上下文中删除的值的数量成比例,即如果$h = 4$并且从上下文中删除/丢失了2个token,PRF仍然有50%的可能性生成相同的哈希。
图2显示,较小的上下文宽度 $h$ 为机器释义提供了最佳的鲁棒性。在更宽的上下文宽度下,Skip和Min变体在攻击下仍然强大,而Additive变体则受到攻击。然而,我们看到这种鲁棒性的改进是以牺牲文本质量为代价的,因为最小方案产生的输出较少。尽管如此,在上下文宽度$h = 4$时,Min-SelfHash方案(棕色圆圈标记)实现了与宽度$h = 1$(黑色圆圈)时的原始Additive-LeftHash方案相同的多样性,同时更加鲁棒。这表明可以使用Min和SelfHash提供的额外强度来运行更长的上下文宽度,从而保护水印。在主体工作的其余部分中,这两种方案将分别称为“SelfHash”和“LeftHash”。附录A.2进一步探讨了 scheme 选择对文本质量的句法和语义方面的影响。

3.2 Improved Watermark Detection
当带水印的文本与无水印的文本穿插在一起时,原始 z-test(Equation(2))可能不是最优的。考虑在一个大得多的无水印文档中嵌入一段带水印的文本的情况。因为 z-score 是在整个文档上全局计算的,所以它被稀释了,因为周围的文本降低了平均 green list 概率。
本文设计了一个叫做WinMax的窗口测试,即使在很长的文档中也能准确地检测到水印区域。这是制定检测假设的另一种方法,可以选择性地使用或与原始测试结合使用,并且不需要修改生成方案。给定一个 token 序列,我们首先在每个 token 的基础上对序列进行评分,以找到命中 $s \in {0, 1}^T$ 到每个 green list 的二进制向量,我们可以将其转换为部分 sum 表示 $p_k = \sum_{i=1}^k s_i$。WinMax搜索对 tokens 产生最高 z-score 的连续span。更正式地说,它可以计算:

由于该测试涉及多个假设检验,我们随后根据与无水印文本的比较校准为固定的假阳性率。
我们进一步研究了一种基于加水印和未加水印文本之间的运行长度差异的更复杂的异常检测器 [Bradley, 1960]。然而,我们发现在我们在这项工作中考虑的设置范围内,这样的检测器在 z-test 和 WinMax 上没有收益。我们在 附录A.5 中简要描述了这种替代检测算法,作为未来研究的起点。
4 Evaluating Watermarking in the Wild
水印在简单的场景中是非常准确的,在这种场景中,长跨度(50多个标token)的文本被孤立地测试,而且不会被修改。然而,在许多用例中,生成的文本将嵌入到更大的文档中,或者由人工编辑,或者由另一种语言模型转述。这些修改可能是为了增加文本的效用,或者恶意擦除水印并逃避检测。本节研究在这些更复杂的用例下水印的鲁棒性。
我们假设以下威胁模型:水印文本的用户知道文本被打上了水印,但不知道描述水印的哈希方案、分数 $γ$ 或上下文宽度 $h$。他们通过改写文本的一些(或全部)段落,以逃避检测。
在这种情况下,我们可以通过以下两个观察来理解水印的可靠性:
(1)如果没有对哈希方案的白盒访问,用户从原始文本中重复使用长单词(通常包含多个tokens)或短语,水印将保留下来,尽管强度降低了。
| (2)如果改写的文本稍微偏向水印行为,那么只要有足够的 tokens,水印就会被检测到。假设每个 token 比随机的 baseline 更可能是 Green 的概率只有 $ε$,即 | $s$ | $= γT(1 + ε)$。那么,对于任何 z-score 阈值,都能期望模型在看过 $T = (z^2−γz^2)/(ε^2γ)$ 个 token 之后就能够检测出水印。 |
由于上述原因,我们不认为转述攻击能够删除水印,特别是在使用现成的人工智能转述工具时,我们怀疑这些工具可能会重复使用短语。相反,这种攻击只是会增加达到自信检测所需要的 token 的数量。这与Chakraborty et al.[2023]的理论分析相吻合,他们断言,对于最优检测器,只要有足够数量的样本,检测总是可能的。
实验设置:遵循Kirchenbauer et al. [2023],本文使用Colossal Common Crawl Cleaned corpus (C4)数据集作为开放式生成的 Prompts。对于 human study,采用了由 y Krishna et al. [2023] 策划的 ”Long-Form Question Answering”(LFQA) 数据集,该数据集基于Reddit “Explain Like I’m Five”(ELI5) 论坛上的一些帖子和对问题的回答,代码实现见GitHub
在本文的大多数实验中,使用 llama [Touvron et al., 2023] 来生成带水印的文本,且用的是有 7 billion 参数的版本。在实验的 human study 部分,我们采用了 Vicuna [Vicuna- team, 2023],这是基础模型的一个微调版本,更适合响应研究中使用的QA提示。附录中还有一部分消融实验。
在所有实验中都使用同一组语言模型采样参数,在 Temperature = 0.7 时进行多项采样;对于所有实验,除非明确说明,不然就是使用基于上下文窗口 $h = 1$ 且 $(γ, δ) =(0.25, 2.0)$ 的加性PRF的 LeftHash 水印方案。这组参数是在Kirchenbauer et al. [2023] 的图2的帕累托边界附近观察到的,非常容易检测,但对生成能力几乎没有影响
由于文本长度在包括水印在内的检测方法的性能中的重要性,我们首先通过限制模型可以生成的 token 数量来仔细控制和指定每个实验中考虑的生成长度,然后对结果数据进行子采样,仅对目标长度值周围指定范围内的那些代进行采样。我们使用“T”表示在所有实验部分中考虑的标记数量,除非另有说明,否则我们包括长度在该值周围±25个标记的段落。除特别注明外,所有图中ROC空间图和测量数据均由>500正和>500个负样本,其他类型的点估计也基于>500个样本。
4.1 Robustness to Machine Paraphrasing Attacks
本文运行了一系列转述攻击 paraphrasing attacks,而且使用了强大的公开可用的通用语言模型API来改写文本。这与 Kirchenbauer et al. [2023] 的攻击模型不同,他们只用了描述能力较弱的模型T5。本文的 “GPT” 转述攻击使用 GPT-3.5-turbo 来重写文本,这是支持 ChatGPT 的模型的一个版本。我们还尝试了一种专门定制的转述模型——Krishna et al. [2023] 使用的 11B Dipper模型 。本文设计 GPT Prompts 以获得最佳的改写性能 。我们的研究包括明确指示 LLM 不要从原始文本中回收 bi-grams 的Prompts,尽管这里没有报告这些结果,因为它们不是性能最好的提示。关于 Prompts 的设计细节参阅附录。本文注意到,当对较长的输入进行 prompte 改写时,GPT 通常会有效地总结文本,有时会将长度减少 $50%$ 以上——这对水印来说是一个有趣的挑战。
以这种方式攻击水印的主要实验结果总结如图3所示。请注意,这里没有显示“未受攻击”的ROC-AUC,因为在这些token 长度下,LeftHash和SelfHash的检测性能总是 $>0.999$。
先看 GPT或Dipper 的攻击结果,攻击前后的 tokens 长度大约为 $T = 200$,我们看到攻击让AUC下降了 $0.05$ - $0.15$ 点。当攻击前的长度为 $600$ 时,尽管 Dipper 和 GPT 分别将长度减少到 $500$ 和 $300$ ,AUC只下降了不到 $0.1$ 点。
这种对可观测 tokens 的数量依赖是水印方案的基本属性,因此,本文通过使用“detectability @ T”图进一步研究。这里对前缀长度 $T_i \in [1,…T]$ 进行测试并计算每个前缀长度的ROC-AUC,然后可视化观察到的 tokens 数量对检测率的影响(简称为 AUC @ T)。附录中显示了 low FPR 下的 TP 率。在这种分析视角下(图4),在未受攻击时,AUC @ T 接近 $1.0$;在受到攻击时,所有方法的 AUC 都降低了,特别是在 $200$-$300$ 个 tokens 的时候转述攻击很成功,但是在有 $600$ 个tokens时,水印的AUC基本能恢复到大于 $0.9$。


4.2 Robustness to Copy-Paste Attacks
本文又设计了一种 synthetic 但 realistic 的攻击方法:将带水印的文本片段嵌入没有水印的人类编写的文档中。这创建了异构示例:只有少数文本的子跨度包含异常高数量的绿色标记,表示水印。
攻击方法有两个参数:(1)插入的 watermarked span 的数量,(2)为带水印的文本的比例。例如,假设一个文本的 $10\%$ 是 watermarked tokens,并且有 $3$ 处插入。如果原始文本有 $1000$ 个 tokens,则文本被插入的 $3$ 个 watermarked span 分别包括 $33$ 个 tokens。这操作称为“$CP-3-10\%$”,即“Copy-Paste with $3$ spans at $10\%$ watermarking”。
回到图3,在水印剩余 $25\%$ 的情况下,复制粘贴攻击对水印的影响要比其他两种 machine based attacks 强得多。对于 $200$ 个tokens,AUC降至 $0.7$ 以下,对于 $600$ 个tokens,AUC降至 $0.85$ 以下。在图4中,水印可检测性的增长速度比未受攻击的曲线慢,但它仍然稳定增长。我们将在第4.4节中重新讨论这种特征的稳定增长行为,并将水印与其他检测方法进行比较。
4.3 Paraphrasing by Human Writers
人类可能会改写带有水印的文本,可能为了逃避检测或单纯改变风格或语气,水印应该对此鲁棒。
为了可靠地测试逃避的可行性,本文进行了 human study。本文招募了 $14$ 名有经验的人类作家(研究生),他们被呈现了水印文本。他们被要求改写文本,目的是在大致保持原始段落长度和语义内容的同时去除水印。除了参与奖励,表现最好的三个人还会获得一张价值100美元的礼券,以激励他们坚定而忠实地复述。此实验的界面如图5所示。每个人类写手都有一组不同的文本段落,通过使用LFQA数据提示带水印的Vicuna版本来生成这些段落。

我们首先使用P-SP [Wieting et al., 2022]分数验证了所有人类写手都成功地改写了文本段落。我们发现P-SP得分远远超过了 Wieting et al. [2022] 认为的专家转述阈值 $0.7$。图6(Left)中显示了每个写手的分数,P-SP直接与基于转述文本检测的 z-scores 进行比较。
然后,通过图6(Right)和图7(Right)中的 z-scores 分析水印的可检测性。在这里,水印强度被表示为 $T$ 的函数,即检测过程中看到的 tokens。虽然人类写手在性能上超过了 machine-based paraphrasers,但都遵循第4节的规律,平均在 $800$ 个标记之后,水印的证据就会增加,甚至可以清楚地检测到人类写手。图7展示了个人表现情况,本研究中唯一真正的例外是人类写手$13$,他是一个强大的转述者,但却没有提交足够的文本来检测。另一个极端是人类作家$22$和$15$,显然是用一种对水印没有实质性影响的策略改写了文本,并且在大约$250$个 tokens 或$200$个 words 后就能被可靠地检测到。


4.4 A Comparative Study of Detection Algorithms
存在许多替代水印的方法。如第2节所讨论的,其他方法有基于统计特征的 post-hoc detectors、black-box learned detectors 和 retrieval systems。本文研究了 DetectGPT(post-hoc,Mitchell et al. [2023])、retrieval-based detection(Krishna et al. [2023])。
Retrieval:Krishna et al. [2023] 的检索系统需要创建和维护一个综合数据库,该数据库包含先前由语言模型生成的所有序列。通过利用语义相似性作为检索机制,如SP [Wieting et al., 2022]或BM25 [Robertson et al., 1994],该方法旨在识别并将改写代后的文本映射到原始的、未损坏的原始文本。本文实验采用 Krishna et al., 2023 的设置,并用BM25搜索。附录中描述了如何用 copy-paste attacked 评估基于检索的方案。
DetectGPT:DetectGPT [Mitchell et al., 2023]是一种用于检测机器生成文本的 zero-shot post-hoc method。它利用曲率 curvature,比较候选通道及其微小扰动之间的对数概率。DetectGPT背后的直觉是,机器生成的文本倾向于支配 LM 对数概率曲线的负曲率区域。本文使用 DetectGPT 的官方实现,并通过使用 T5-3B [rafael et al., 2020]作为生成扰动的 mask-filling model。本文对每个测试样本产生100个扰动,并以 normalized perturbation discrepancy 作为标准。关于该方法适应性的进一步细节在附录。
Which method is most reliable? ** 使用GPT、Dipper和 copy-paste attack 开始评估。图8**中绘制了每种检测方案的ROC图,其中每种方法都有一个长度为 $T = 1000$ 的文本段落用于检测。结果显示,检索和水印都是不错的检测方法,并且比 post-hoc(其中DetectGPT已经是最强的)更可靠。然而,尽管基于检索的方案在 GPT和Dipper 的攻击下表现优于水印(符合 Krishna et al. [2023] ),但在 copy-paste 攻击中,水印表现更好。

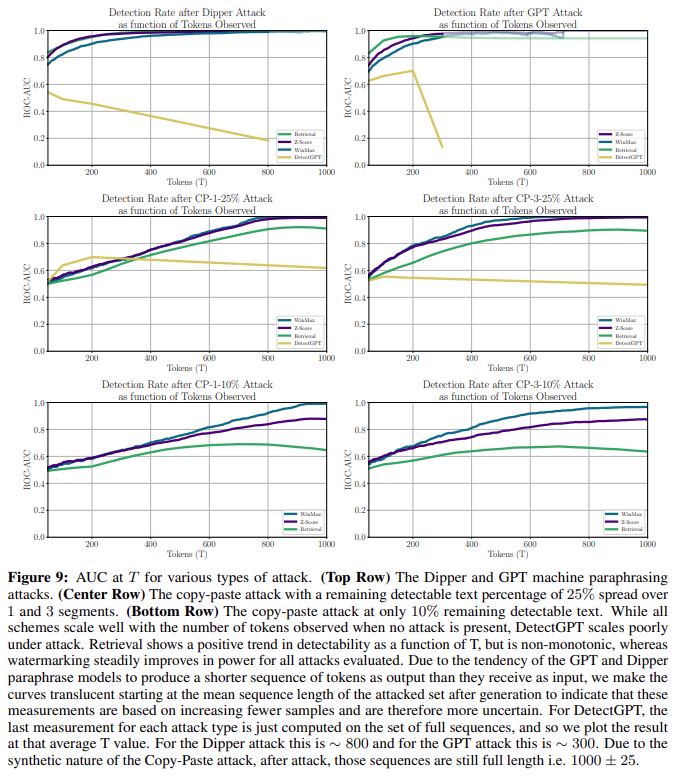
The Sample Complexity of Various Detection Schemes. **本文还比较了 AUC @ T,即检测性能再次作为文本数量的函数。如图9**所示,更多细节在附录。
通过观察检测方法的缩放行为在攻击下的明显不同来解释水印优于检索:
虽然当生成的文本没有受到严重攻击时,所有方法的强度都随文本长度适当缩放,但在强攻击下,只有水印可靠地继续改进,与第4节一致。特别是,当只有一小部分文本($25\%$或$10\%$)受到 copy-paste 攻击时,非水印方法会随着文本长度的增加而受到影响。对于检索方法,随着 $T$ 的增加,原始文本(未受攻击的正样例)的剩余部分减少,与原始示例的相似度继续下降,最终在 copy-paste 攻击严重时性能下降。DetectGPT类似且更加明显。在附录A.8中,通过检查在每种方法的每种攻击设置下产生的实际检索和检测分数的趋势来更详细地研究这种行为。
4.5 What about the White-Box Setting?
在这项工作中,我们专注于 black-box setting,其中文本在机器生成文本的合理用例中被修改,并且编辑修改文本的一方不知道水印方案的密钥。
一旦这个假设被放宽,例如,如果密钥被泄露或水印是公开的,那么攻击者可以通过 white-box 访问像 Dipper [Krishna et al., 2023] 这样的强转述模型,并通过以下方式破坏水印:攻击者可以在转述模型生成过程中使用反水印方案,不是将 **Equation (1) ** 中的 $δ$ 添加到 $logit$ 输出中,而是减去$δ$。攻击者可以进一步跟踪 green-listed 与red-listed tokens 的当前分数,并相应地动态修改该 $negative δ$ ,以保证由转述模型生成的文本的 $T$ 个 tokens 中 $γT$ 完全为 Green,并且没有水印信号泄露到转述文本中。
这种攻击既依赖于对水印密钥的白盒访问,也依赖于强转述模型的可用性。为了绕过这个困难的威胁模型,必须选择足够大的水印上下文宽度 $h$ ,以便在对抗场景中不容易被发现水印密钥(或者,必须同时使用足够多的密钥,如Kirchenbauer et al. [2023]所讨论的那样)。然而,并非所有的水印用例都是对抗性的,我们坚信,在良性的情况下,即使水印对文本损坏的抵抗能力不完美,也仍然是非常有价值的。全面记录机器生成文本的使用情况,例如,事后追踪生成文本的传播,或者从未来的训练运行中删除生成文本 [Radford et al., 2022, Shumailov et al., 2023],可以为 “future-proof” 的生成模型提供基本的贡献。
5 Relationship to theoretical results on (im)possibility of detection
一些工作从理论 [Varshney et al., 2020, Sadasivan et al., 2023, Chakraborty et al., 2023] 和实践 [Bhat and Parthasarathy, 2020, Wolff and Wolff, 2022, Tang et al., 2023] 的角度研究了检测语言模型的难度,尽管这些工作大多属于post-hoc探测器。本节介绍这些工作与寻找水印可靠性的经验证据之间的关系。
Sadasivan等人[2023]在他们关于LLM水印和检测的不可能性的工作中,假设检测的目标是区分由大型语言模型生成的文本和从某些人群中随机抽样的人生成的文本,例如来自Twitter用户的tweet。Sadasivan等人[2023]也假设大型语言模型训练的目标是模仿这种人类语言分布。如果LLM完美地模拟了这种分布,那么它生成的样本将与人类样本无法区分。但是在某种程度上,LLM不完全模仿人类的分布,Chakraborty等人[2023]证明,在足够数量的样本下,可以检测到语言模型和人类书面文本之间的分布变化。如果LLM遵循更集中的文本分布,例如,经常性地以特定个体而不是随机采样的语气生成样本,这些样本将不太可能符合一般的人类分布,因此能被检测到。
现有文献表明,用标准方法训练的 LLM 不会模仿随机抽样的个体——已知用于训练 LLM 的标准分类损失奖励与典型人类文本有着不同的低熵输出分布 [Holtzman et al., 2019, Gehrmann et al., 2019]。此外,善意的用户,以及将 LLM 作为一种服务出售的公司,很少希望 LLM 模仿一般的人类语言分布,相反,他们可能更喜欢非人类可理解的事实文本,或者用优雅的专业语气写的文本。
不管未来的 LLM 是否模仿人类的分布,水印仍然是可行的。考虑到通用的人类语言分布非常分散,对于一个 prompt 可以得到许多有效的补全。例如,不同的数学家对同一个定理写出了独特而正确的证明,即使他们的逻辑步骤是相同的,这表明即使是看似答案狭窄的任务,比如数学,实际上可能仍然承认人类语言的分散分布。
补全文本上的 high entropy 使水印能够将模型输出集中在有效补全的子集上,同时仍然将大多数注意力分散在不同的高质量候选上。事实上,只要有足够的样本,就可以检测到只对生成分布产生很小变化的水印,Chakraborty et al. [2023] 在理论上证明了这一点,我们自己的工作也验证了这一点。此外,水印的好处是我们可以以一种优化可检测性的方式最小限度地改变生成分布。
虽然 Sadasivan et al. [2023] 也指出,水印可以通过从具有相同内容的文本集中采样的 paraphraser 来去除。不过到目前为止,这种理论上最优的解释还没有得到证实。我们的实验表明,即使是更强的模型(ChatGPT)也可能不足以对较弱的模型(LLaMA-7B)产生的水印进行转述攻击。这表明在现有 paraphrasers 水平情况下,水印仍然是可行的方案。
最后,讨论语言分布差异的理论文献并没有触及检测问题的核心。现有的 post-hoc 检测器失败,主要是因为我们缺乏对其差异的数学表征 [Liang et al., 2023, Krishna et al., 2023],而不是因为人类编写的文本和机器生成的文本的分布相似。例如,考虑一个带有伪随机采样器和固定种子的 LLM。每个 token 都是前一个 token 的确定性函数。输出分布集中在基于 prompt 的单个示例上,使其与人类分布非常不同。然而,如果没有白盒模型访问,在实践中检测仍然很困难,因为我们既不知道 LLM 的峰值位置,也不知道人类文本的分布。相反,水印之所以有效,并不是因为它引起的分布位移大,而是因为这种位移有一个简单的规律。在水印之前,人类编写的文本和机器生成的文本分布可能相差很大,但需要对差异进行表征才能进行检测。
6 Conclusions
通过全面的实证调查,包括强机器和人类转述,本文评估了水印作为机器生成文本的记录和检测机制的可靠性。本文主张将水印可靠性视为文本长度的函数,并发现即使是人类作家也不能可靠地去除1000个单词的水印,尽管有去除水印的目标。这种将水印可靠性视为文本长度函数的观点是水印的一个重要特性。当与其他范例(如检索和基于损失的检测)进行比较时,并没有发现文本长度对这些方法有促进效果,这使得水印在本研究中被认为是最可靠的方法。这种可靠性是检测器依赖于人类始终坚持的 null hypothesis 的结果,独立于文本长度,因此产生严格且可解释的 P-value,用户可以利用该值来控制误报率。