
Abstract
人工智能模型生成的内容对世界各地的教育工作者提出了相当大的挑战。当学生提交AI生成内容(AIGC)作为自己的工作时,教师将需要能够用肉眼或借助一些工具检测此类文本。对AIGC的词法、句法和文体特征的了解也越来越迫切。
为解决英语语言教学背景下的这些挑战,本文首先提出ArguGPT,一个精心平衡的语料库,由7个GPT模型根据三个来源的文章提示生成4,038篇议论文:(1)课堂或家庭作业,(2)托福写作任务和(3)GRE写作任务。这些机器生成的文本与数量大致相等的人工撰写的文章相匹配,在文章提示中得到低、中、高的分数。
然后,我们聘请英语教师来区分机器论文和人类论文。结果显示,当教师第一次接触到机器生成的论文时,他们识别它们的准确率只有61%。但经过一轮最低限度的自我训练后,这个数字上升到67%。对机器和人工作文进行了语言分析,结果表明,机器生成的句子具有更复杂的句法结构,而人工作文往往在词汇上更复杂。最后,我们测试了现有的AIGC检测器,并使用svm和RoBERTa模型构建了我们自己的检测器。实验结果表明,使用ArguGPT训练集对RoBERTa进行微调后,在文章级别和句子级别的分类中都可以达到90%以上的准确率。
据我们所知,这是第一次对生成式大型语言模型产生的议论文进行全面分析。本文工作表明,教育工作者需要了解AIGC,介绍了人工智能生成议论文的特点,并表明从同一领域检测AIGC似乎是基于机器学习分类器的一项简单任务。机器撰写的论文和我们的模型将在 https://github.com/huhailinguist/ArguGPT 上公开。
1 Introduction
三个问题:
- 人类评价者(语言教师)能区分由GPT模型生成的英语议论文和人类语言学习者写的英语议论文吗?
- 与语言学习者的作文相比,机器生成的作文有什么语言特征?
- 机器学习分类器能区分机器生成的作文和人工写作的作文吗?
为回答这些问题,本文首先使用GPT家族的七个模型(GPT2-XL、GPT3的变体和ChatGPT)收集了4038篇机器生成的论文,以响应来自多个级别的英语熟练程度和写作任务(课堂写作练习、托福和GRE)的632个提示。然后,将这些文章与4,115篇人工撰写的低、中、高水平的文章进行配对,形成ArguGPT语料库。该文对43名中国英语新手和有经验的英语教师进行了人工评价测试,以识别一篇文章是机器写的还是人写的。随后,该文利用Lu(2010, 2012)的工具和方法,对人工作文和机器生成作文的31个句法和词汇语言学指标进行了比较,旨在揭示gpt生成作文的文本特征。最后,在ArguGPT语料库的开发集和测试集上对现有的AIGC检测器GPTZero4以及基于SVM和RoBERTa的AIGC检测器进行测试。
我们的主要发现和贡献是:
- 本文为NLP和ESOL研究人员提供了第一个大规模、平衡的ai生成的议论文语料库。
- 英语教师很难识别gpt生成的文本。英语教师在第一轮中区分人工和gpt撰写的文章的准确率为61.6%,在经过一些最小的训练后,准确率上升到67.7%,比Clark等人之前的报告(2021)高出大约10分,这可能是由于教师熟悉学生写的文本。有趣的是,它们更擅长检测低级别的人工论文,而不是高级的机器论文。
- 在句法和词汇的复杂性方面,我们发现,最好的GPT模型生成的句子在句法上比人类(英语语言学习者)更复杂,但GPT撰写的文章往往在词汇上没有那么复杂。
- 本文发现,机器学习分类器可以很容易地区分机器生成的作文和人工撰写的作文,通常具有非常高的准确性,这与Guo等人(2023)的结果类似。GPTZero在文章级别和句子级别上都有90%以上的准确率。表现最好的RoBERTa-large模型在ArguGPT上进行了微调,在测试集上的文章水平上达到了99%的准确率,在句子水平上达到了93%。
- 机器撰写的文章将在 https://github.com/huhailinguist/ arggpt上发布。我们的ArguGPT检测器和相关模型的演示可以在 https://huggingface.co/spaces/SJTU-CL/argugpt-detector 上找到。
4 Linguistic analysis
本节比较机器和人写作的语言特征,其中,文本按作者分成10组:1)低水平人类,2)中等水平人类,3)高水平人类,4)gpt2-xl,5) text-babbage-001,6) text- curcie -001,7) text-davinci-001,8) text-davinci-002,9) text-davinci-003,10)gpt-3.5-turbo。
首先进行描述性统计。然后,用第二语言(L2)写作研究中既定的措施和工具来分析人类和机器书面文本的句法复杂性和词汇丰富性(Lu, 2012,2010)。
4.1 Methods
Descriptive statistics:我们使用内部Python脚本和NLTK (Bird, 2002)在以下5个方面获得文章的描述性统计:1)平均文章长度,2)每篇文章的平均段落数,3)平均段落长度,4)每篇文章的平均句子数,5)平均句子长度。
Syntactic complexity:为了分析文章的句法复杂性,我们使用L2句法复杂性分析器来计算每个文本的14个句法复杂性指数(Lu, 2010)。这些方法在L2写作研究中得到了广泛的应用。表11给出了索引的详细信息。然而,Lu(2010)报告的这14项措施中只有6项与语言能力水平线性相关,因此我们只给出了这6项措施的结果。

Lexical complexity:词汇的复杂性或丰富性是文章质量的一个很好的指标,被认为是检验第二语言学习者熟练程度的有用和可靠的措施(Laufer and Nation, 1995)。许多二语研究都讨论了评估词汇复杂性的标准。在本研究中,我们效仿Lu(2012)比较了语言习得文献中的26种测量方法,并开发了一个计算系统,从词汇密度、词汇复杂度和词汇变异三个维度来计算词汇丰富度。
词汇密度是指一篇文章中词汇数量与词汇总数的比值。我们遵循Lu(2012)的定义,将词汇定义为名词、形容词、动词以及带有形容词词根的副词,如“well”和后缀为“-ly”的单词。情态动词和助动词不包括在内。词汇复杂度计算文本中高级或不常见的单词(Read, 2000)。我们进一步将复杂的单词操作为词汇单词,以及不在美国国家语料库中生成的2000个最常见单词列表中的动词。词汇变异指的是不同词汇的使用,反映了学习者的词汇量。
具体来说,我们使用Lu(2012)的词法复杂性分析器来计算每篇文章的25个指标。具体计算方法和公式见附录G表28。我们使用spaCy (Honnibal and Johnson, 2015)对所有文章进行 tokenization 和 POS-tagging。
N-gram analysis:我们使用NLTK包从人类和机器的文章中提取trigrams,4-grams和5-grams,并计算它们的频率,以找出人类和机器文章中的使用偏好。然后,我们为每个N-gram计算对数似然(Rayson和Garside, 2000),以发现在机器或人类论文中过度使用的短语。
4.2 Results
4.2.1 Descriptive statistics
ArguGPT语料库中子语料库的描述性统计信息如图2所示。对于人类来说,分数越高的文章可能从文章层面和段落层面都有更长的长度,并且一篇文章中的段落和句子更多。然而,这三个层次的人写的句子长度相似。
同样,更高级的机器“英语学习者”可能会有更长的文章长度,更多的段落和句子。然而,段落的平均长度从gpt2-xl到text- davincii-001是减少的,从text- davincii -002到gpt-3.5-turbo则是增加的。在平均句子长度方面,text- davincii -002是机器中句子最短的。
不同的机器在某种程度上匹配不同水平的人在平均文章、段落和句子水平上的表现。然而,在段落长度方面,人类作家胜过机器作家(这有什么意义吗?)。

4.2.2 Syntactic complexity
图3给出了按ArguGPT语料库中的子语料库分组的文章的六个句法复杂性值的均值。
如图3所示,所有6个选择的句法复杂性值在人类论文的3个分数水平上呈线性进展。它们还表明,随着发展的顺序,语言模型之间存在着普遍的增长趋势。值得注意的是,text- davici-002在这些度量中比以前和后来的模型都要差。根据MLT(Mean length of T-unit)和CN/T(complex nominals per T-unit),gpt2-xl的性能甚至优于text- davici-002。
当我们将人类论文与机器论文进行比较时,即使是高水平的人类英语学习者在所有6项指标中也被gpt-3.5-turbo和text- davincii -003所超越。这对于CP/T和CP/C来说尤其如此,这表明后两种模式的文章中 coordinating phrases 比人类学习者的文章更常见。另一方面,gpt2、text-babbage-001、text-curie-001 和 text- davincii -001/002 在这些方面似乎与人类学习者不相上下。
我们用上述结果表明,一般来说,更强大的模型,如 davice -003 和 ChatGPT,甚至比高水平的英语学习者产生更复杂的语法文章。

4.2.3 Lexical complexity
ArguGPT语料库的词汇复杂度如图4至7所示(实际数字请参见附录中的表29和表30)。我们观察到以下模式:
-
高级非英语母语者的词汇量比gpt-3.5-turbo丰富,即在机器中表现最好,而中级和初级L2英语学习者的词汇复杂性比gpt-3.5-turbo差
-
高级英语学习者或精通写作技能的英语母语人士仍然超过gpt-3.5-turbo
-
从gpt2-xl到gpt-3.5-turbo,这些模型的词汇复杂性通常是逐步增加的
-
人类比机器更倾向于使用多样化的词汇。在我们的三个语料库中,高级 L2 英语使用者在词汇词类的 type-token ratio 指标上超过了机器,表明词汇词类的变化是AIGC检测器的潜在指标。
图4中的词汇密度显示,与text-davinci-003和gpt-3.5-turbo相比,人类短文倾向于使用更多的虚词,因为这两种模型更喜欢使用更多的词汇。
至于词汇复杂程度(如图4所示),高水平的第二语言学习者在所有五个指标(词汇复杂程度1/2和动词复杂程度的三个指标)上都优于或与gpt-3.5-turbo水平相当。
就动词的复杂程度而言(图4的下半部分),低/中等水平和高水平的人类写作之间的差异是明显的。高级学习者超过gpt-3.5 turbo,中级水平与text-davinci-003相当。然而,高水平的人类论文在WECCL中的表现不如gpt-3.5-turbo。此外,GRE论文在这三项指标上的值远高于WECCL和TOEFL,特别是对于高级水平。我们将此归因于我们GRE语料库的性质,其中文章都是为准备GRE考试的人提供的示例文章,而不是代表所有水平的考生。
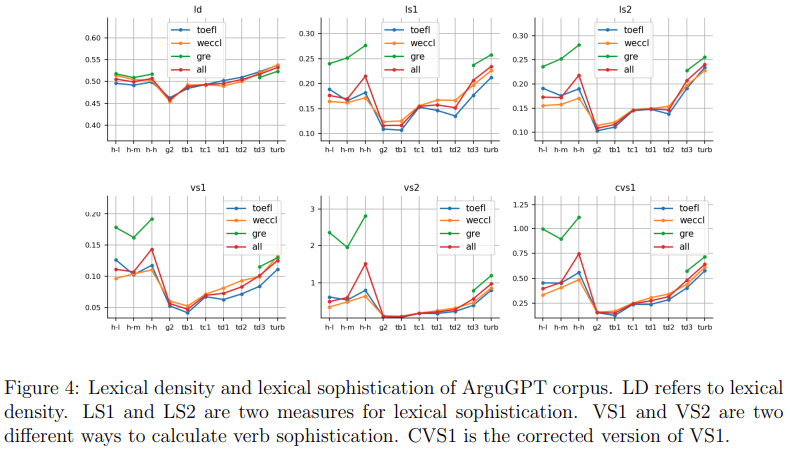
词汇变化的度量如图5(不同单词的数量)、图6(类型-标记比)和图7(词类的类型-标记比)所示。它们表明学习者词汇的范围和多样性。
在图5所示的四个不同单词数量的测量中,高级学习者在两个指标上超过了gpt-3.5-turbo。Text-davinci-003和gpt-3.5-turbo分别相当于中、高水平的L2说话者的写作水平。除了GRE语料库外,WECCL和TOEFL语料库的趋势也类似。我们的GRE作文词汇量最大,在三个指标上超过了gpt-3.5-turbo。

Type-token ratio (TTR)是衡量词汇丰富度的重要指标。图6中TTR的六个指标都表明,虽然gpt-3.5-turbo在WECCL和TOEFL中表现优于中等水平的考生,但机器的表现与熟练的非母语人士之间仍有明显的差距。所有级别的GRE考生都超过了机器。需要强调的是,与CTTR (corrected TTR)及其变体相比,TTR并不是标准化的,文章越短,TTR越高。因此,gpt2-xl生成的论文具有更高的TTR。其他标准化的变体更好地代表了文章的词汇丰富性。

对于每个词类,可以进一步研究 Type-token ratio。图7显示了词汇和其他五种比率的变化,包括动词、名词、形容词、副词和修饰语。我们观察到高级学习者在三个语料库中的所有指标上都优于gpt-3.5-turbo。在词汇、动词、名词和副词中,这种空白处很明显,我们还需要进行统计测试来衡量这些差异。注意,与其他指标相比,SVV1和CVV1是标准化的,可能更适合分析差异。动词系统被认为是第二语言习得的重点,因为它是构建任何语言的关键部分(Housen, 2002),人类在丰富的动词应用方面比机器表现出更强的能力。

4.2.4 N-gram analysis
表12列出了语言模型比人类更频繁使用的20个三元组。值得注意的是,“i believe that”在3338篇机器生成的论文中出现了2056次,而在3415篇人类论文中只出现了207次。这似乎是text- davincii -001的口头语,在text- davincii -001生成的509篇文章中出现了503次,而gpt2-xl生成的284篇文章中出现的次数只有31次。
表12的右侧列出了20个人类使用频率高得多的三元组。从log-likelihood的值可以看出,人和机器使用这些短语的差异并不像机器过度使用的短语那么大。但仍然值得注意的是,“more and more”在人类写作中出现的频率要高得多。当我们在托福语料库(包含11种不同母语的英语学习者写的文章)中查看这个短语的使用情况时,我们发现第一语言是汉语或法语的学生更喜欢这个短语。

4.3 Summary
综上所述,语言分析结果表明,在句法复杂性方面,textdavincici -003和gpt-3.5-turbo生成的文章比大多数ESOL学习者生成的文章更复杂,特别是在与协调短语相关的度量上,而其他模型与我们语料库中的人类文章相当。
对于词汇复杂性,像gpt2-xl、text-babbage/curie-001和text-davinci001/002这样的模型,在大多数情况下,在几个方面与初级/中级英语学习者相当,而text-davinci-003和gpt-3.5-turbo大约处于高级英语学习者的水平。对于一些词汇丰富度测量(例如动词复杂程度)和GRE论文,我们的人类数据比最好的人工智能模型显示出更大的复杂性。
换句话说,机器生成的句子更长,句法更复杂,但与人类作家(在我们的例子中主要是英语学习者)相比,机器使用的单词可能更少丰富和多样性。
此外,从N-gram分析中,我们发现机器更喜欢“i believe that”、“can lead to”和“more likely to”这样的表达,而这些短语在我们人类撰写的文章中很少使用。
此外,我们发现随着模型的发展,词汇/句法复杂性有增加的总体趋势,但从某些方面来看,gpt2-xl和text-davinci-002似乎是例外。