ABSTRACT
1 INTRODUCTION
2 RELATED WORK
3 METHOD
4 EXPERIMENTS
4.1 Datasets
公开可用的数据集,意思是要读者自己收集:
- CiFake [7],The generation of synthetics is carried out by a LDM model[69].
- ArtiFact[6],we select 10,500 real and generated images with 5,250 images per category.
- DiffusionDB[95],
- The synthetic dataset consists of DM-generated images from 25 distinct methods, including 13 GANs, 7 Diffusion, and 5 other miscellaneous generators. we randomly select images from six diffusion models (Glide, DDPM, Latent Diffusion, Palette, Stable Diffusion, VQ Diffusion) [56, 37, 69, 74, 69, 33] and six GAN models (Big GAN, Gansformer, Gau GAN, Projected GAN, StyleGAN3, Taming Transformer) [10, 41, 60, 77, 44, 24]
- In our study, we work with the subset
“2m random 5k”[91],inspired by Xie et al. [97], we employ LAION-5B and SAC datasets (see below) as the real dataset
- LAION-5B[79],Although this dataset provides different image sizes, we focus only on the high-resolution [47] subset. Note that the images are center cropped to fit the synthetic datasets.
- SAC[64],The images in version 1.0 of SAC are provided as a subset in https://s3.us-west-1.wasabisys.com/simulacrabot/sac.tar . We only filter the images with size 512 × 512 pixels
作者自己搞的数据集,具体看附录E。GitHub还没给!
-
Stable Diffusion-v2.1 (SD-v2.1),使用预训练模型 [69, 84] 生成 2000 张样本,生成的方式是用LAION-5B的prompts作为提示。对应的真实数据集就用LAION-5B
-
LSUN-Bedroom,从[90]里用了好多种生成方法生成 2000张图片/每个方法:
- {DDPM, DDIM, PNDM}-ema,版本: id
“google/ddpm-ema-bedroom-256”includes DDPM, DDIM, and PNDM samplers - ADM,版本:the pre-trained LSUN-Bedroom model of ADM [20] from the official repository [59]
- SD-v2.1,版本:“stabilityai/stable-diffusion-2-1” [69]
- LDM,版本:id
“CompVis/ldmtext2im-large-256”[69] - VQD,版本:id
“microsoft/vq-diffusion-ithq”[32]
然后真实数据集就用 the images from LSUN-Bedroom dataset [98] from huggingface [18],并裁剪成256*256 pixels
- {DDPM, DDIM, PNDM}-ema,版本: id
4.2 Experimental Setup
数据预处理:所有实验均在上述数据集上进行。首先,我们计算数据集的标准均值和标准差,并对输入进行归一化。一旦我们有了均匀的数据分布,我们将图像输入一个未经训练的ResNet18模型[36](As a ResNet18 implementation, we use the model provided by TIMM library https://huggingface.co/docs/timm/index. The selected layers are called: 1_conv2_1, 1_conv2_2, 2_conv2_1, 2_conv2_2, 3_conv2_1, 3_conv2_2, 4_conv2_1, 4_conv2_2., which has the advantage to manage all different image sizes.)来提取它们的特征。虽然网络没有经过训练[4,11,16],但它已经足以提炼出数据的主要特征。通过使用未训练或训练过的权重(参考附录C),我们没有观察到检测器准确性的差异。然后,我们从提取的特征图中计算multiLID分数。训练数据大小为每个类1,600个样本,除非实验中另有规定,最后我们在标记的multiLID分数上训练随机森林分类器。
评估指标:在之前的检测方法[100,92,93,94]的基础上,我们也在实验中报告了准确性ACC。
4.3 Classification
4.4 Model Strength Assessment
4.5 Identification and Transferability Capability Evaluation
5 CONCLUSION
APPENDIX
A. New Datasets
除了4.1.2节中“new datasets”类别中的数据集外,还使用了:
- CIFAR-10-DDPM-ema,用预训练好的DDPM 生成2000张图片。真实图片则来自 CIFAR-10 dataset [46] 。
- Oxford-Flowers-64-DDPM-ema,使用预训练的DDPM模型[90]生成2000张图片,模型版本id为
flowers-102-categories。真实图片则来自 diffuser dataset 的huggan/flowers-102-categories。 - CelebaHQ-256-{DDPM, DDIM, PNDM, LDM}-ema,使用预训练的DDPM, DDIM,PNDM和LDM模型[90]生成2000张图片/per method,模型版本id为
google/ddpm-ema-celebahq-256和CompVis/ldm-celebahq-256。真实图片则来自CelebaHQ[42],裁剪大小256 × 256像素。 - LSUN-Cat-{DDPM, DDIM, PNDM}-ema,使用预训练的DDPM, DDIM和PNDM模型[90]生成2000张图片/per method,模型版本id为
google/ddpm-ema-cat-256。真实图片则来自[98]。裁剪大小256 × 256像素。 - LSUN-Church-{DDPM, DDIM, PNDM}-ema,使用预训练的DDPM, DDIM和PNDM模型[90]生成2000张图片/per method,模型版本id为
google/ DDPM - emma -church-256。真实图片则来自[98],裁剪大小256 × 256像素。 - ImageNet-DiT,使用预训练DiT模型[90]生成2000张图片,模型版本id为
facebook/DiT- xl -2-256[61],真实图片则来自[19],裁剪大小256 × 256像素。
B. Definition of LID
C. Un/trained Feature Maps
D. Variance of the Strength Assessment
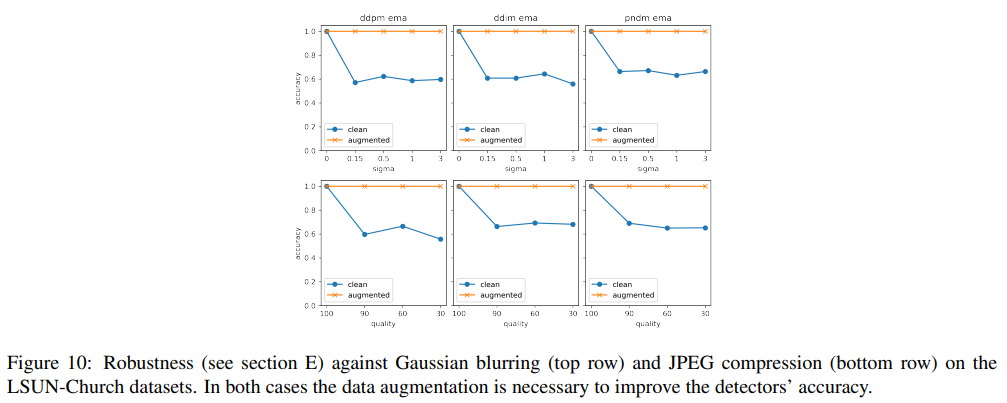
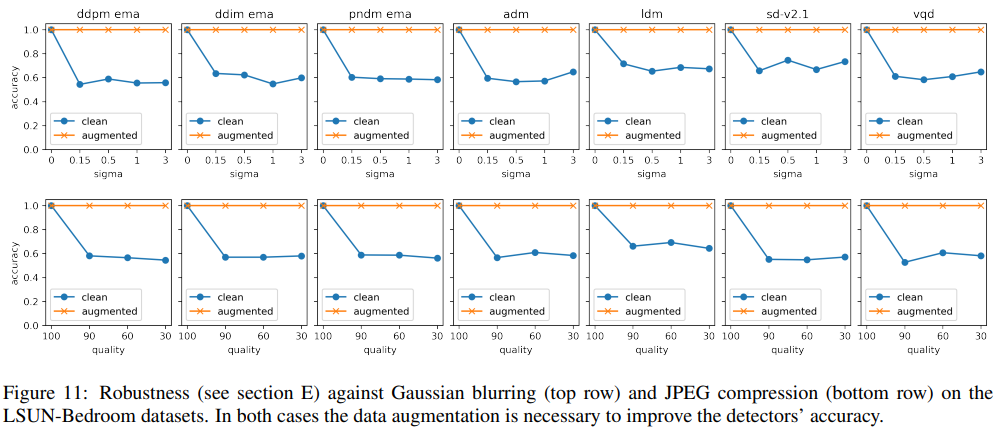
E. Robustness via Data Augmentation
本节是4.3节的扩展,在更多数据集上评估高斯模糊和JPEG压缩。CelbeaHQ(图8)、LSUN-Cat(图9)、LSUN-Church(图10)和LSUN-Bedroom(图11)
用两种标准增强训练手段做实验: mixing the two class degradation 和 参数随机初始化。与[93]类似,用 σ ~ Uniform[0,3] 进行随机高斯模糊(上半部分的横轴),并使用 quality ~ Uniform{30,31,…,100} 进行压缩(下半部分的横轴)。一共是进行了三个独立的实验:
- 无增强:在干净的数据上进行训练和测试。评估指标是准确性(ACC)
- 增强:图像随机高斯模糊,JPEG算法压缩。增强概率设为0.5
- 强增强:类似先前的增强,增强概率大于0.1
从表4中观察到,随着数据的增加,基于multiLID的方法能够对所有劣化(即高斯模糊和JPEG压缩)产生准确的检测结果。